Password Similarity Detection Using Deep Neural Networks
This project was the case study of my bachelor’s thesis.
Source code can be found here
Introduction
Nowadays people tend to create more profiles or change password of their current profiles for security reasons. Existent passwords and literature-based words have a great impact on the candidate password. This could be a risk for the user privacy. For example, an user has the password mum77 and he/she wants to create a new account for a different website. A candidate password could be mommy1977, which is a variation of mum77 and it more risky if an attacker has discovered the first password in a leak.
The purpose of this project is to give a feedback about password similarity between the new password and the old one using Deep Neural Networks. As a reference, a scientific article published at IEEE Symposium on Security and Privacy 2019 chosen. Then the entire architecture was reimplemented and improved, and a comparison between the obtained results and the case study was made.
Data pre-processing
File: preparing_dataset.py
First of all I used a compilation of password leaks containing 1.4 billion email-password pairs from the Deep Web. Further operations were applied on the dataset:
- Passwords longer than 30 characters or shorter than 4 removal.
- Non ASCII printable characters in password removal.
- Bot (which are recognisable by the same mail used more than 100 times) removal.
- HEX passwords (identified by
$HEX[]) and\xremoval. - HTML char set removal, for example:
>&ge<&le-
&#(HTML entity code) amp- Due to the impossibility of similarity detection, accounts with less than 2 password were removed.
After that, two dataset were build:
- The first one, according with Bijeeta et alii, contains all the passwords in key-presses format (using the
word2keypresspackage). - The second one contains all the passwords as they are.
The filtered datasets were saved in two .csv files in this format:
- in the first dataset:
sample@gmail.com:["'97314348'", "'voyager<s>1'"] - in the second dataset:
sample@gmail.com:["'97314348'", "'voyager!'"]
Word2keypress
Every password in the first dataset was translated in a keypress sequence on an ANSI american keyboard:
- Every capital letter was represented by
<s>(theSHIFTkey) before the lowercase version.
e.g.Hello -> <s>hello - If there is a sequence of consecutive capital letters, followed by lowercase letters, the
<c>tag (theCAPS LOCKkey) is inserted before and after the sequence, which will be represented by lowercase letters. e.g.Password -> <c>pass<c>word - If a sequence of capital letters ends at the end of the word, the
<c>tag wil be placed before the sequence.
e.g.
PASSWORD -> <c>passwordpassWORD -> pass<c>word - If a password contains ASCII 128 special characters, the
<s>tag will be placed before the special character, which is translated asSHIFT + <key for the specific character>
e.g.PASSWORD! -> <c>password<s>1Hello@!! -> <s>hello<s>2<s>1<s>1

Splitting dataset
File: split_dataset.py
Both datasets are splitted in training set (which is 90% of the original dataset) and test set (the remaining 10% of the original dataset).
Training FastText
File: FastText_training.ipynb and PasswordRetriever.py
In this file FastText will be trained based on the given training set.
In order to understand better FastText_training.ipynb and FastText, Word2Vec is briefly introduced.
Word2Vec
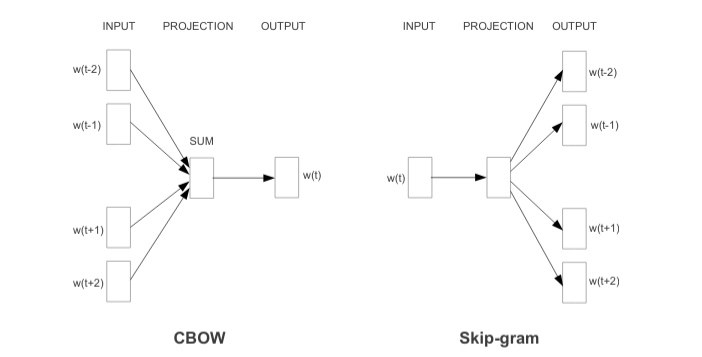
Word2Vec is a set of architectural and optimization models which learn word embeddings from a large dataset, using deep neural networks. A model trained with Word2Vec can detect similar words (based on context) thanks to cosine similarity.
Word2Vec is based on two architectures:
- CBOW (continuous bag of words): the main purpose is to combine the representation of surrounding words, in order to predict the word in the middle.
- Skip-gram: similar to CBOW, except for the word in the middle, which is used to predict words related to the same context.
CBOW is faster and effective with larger dataset, however, despite the greater complexity, Skip-gram is capable to find out of dictionary words for smaller datasets.
FastText
FastText is a open source library created by Facebook which extends Word2Vec and is capable to learn word representation and sentence classification efficiently. The training is based on password n-grams.
N-grams of a specific word that contains n characters are defined as follow:
For example, the ngrams of the word world, with n_mingram = 1 and n_maxgram = 5 are:
world = {
{w, o, r, l, d},
{wo, or, rl, ld},
{wor, orl, rld},
{world}
}
world is represented as the subset of substrings with 1 and 5 as respectively minimum and maximum length.
FastText, comparing to Word2Vec, is capable to obtain more out of dictionary words, which are unknown during the training phase.
Environment setup
In order to train the model, gensim.FastText was used.
gensim is a open source and cross-platform python library, with multiple pre-trained word embedding models.
PasswordRetriever class extracts all the passwords from the .csv preprocessed file.
FastText parameters
negative = 5
subsampling = 1e-3
min_count = 10
min_n = 2
max_n = 4
SIZE = 200
sg = 1
In this project Skip-gram model (sg = 1) and negative sampling were used:
- Skip-gram approach is chosen, as the distributed representation of the input word is used to predict the context. Skip-gram model works better with subword information, so it is recommended for learning passwords and rare words in general.
- Negative sampling makes the training faster. Each training sample updates only a small percentage of the model weights. For larger datasets (like this case) it is recommended to set negative sampling between 2 and 5.
- The dimension of vectors is set to 200, in order to have train the model faster. Generally it is recommended to have
SIZE = 300 - The
subsamplingignores the most frequent password (more than 1000 occurrences). -
min_countrepresents the minimum number of occurences of a password in the training dataset. -
min_nandmax_nare the number of respectively minimum and maximum n-grams. - N-grams are used in statistical natural language processing to predict a word and/or the context of a word. In this case they represent a contiguous sequence of n characters and their purpose is to give subword information.
- For example a password
w = qwertywithmin_n = 4andm_max = 5, will have the following n-grams.
zw = { <qwe, qwer, wert, erty, rty>, <qwer, qwert, werty, erty> }
NB < and > are considered as characters.
Saving the model
Finally, the trained model is saved as .bin.
from gensim.models.fasttext import save_facebook_model
save_facebook_model(trained_model, "model_password_similarity.bin")
print("Model saved successfully.")
More trainings
5 models were trained:
-
word2keypress,epochs = 5,n_mingram = 1(Bijeeta et al.); -
word2keypress,epochs = 5,n_mingram = 2; - no
word2keypress,epochs = 10,n_mingram = 1; - no
word2keypress,epochs = 10,n_mingram = 2; - no
word2keypress,epochs = 5,n_mingram = 2.
Compressing the model
The trained model is 4.8 GB. There are some problems about the size:
- Too much space occupied in memory.
- It is harder to use the model in client/server architectures. Everyone should use this model, which can be sent as a payload. Embeddings are not reversible, and they guarantee password anonymization.
For these reasons, compress_fasttext is used.
import gensim
import compress_fasttext
In order to obtain a compressed model, without impacting significantly on performances, product quantitation and feature selection are applied.
- Feature selection is the process of selecting a subset of relevant features for use in model construction or in other words, the selection of the most important features.
- Product quantization is a particolar type of vector quantization, a lossy compression technique used in speech and image coding. A product quantizer can generate anexponentially large codebook at very low memory/time cost.
big_model = gensim.models.fasttext.load_facebook_vectors('model_password_similarity.bin')
small_model = compress_fasttext.prune_ft_freq(big_model, pq=True)
small_model.save('compressed_model')
The compressed model is 20MB.
Evaluating the model
File: w2kp_PRGraph.py and No_w2kp_PRGraph.py
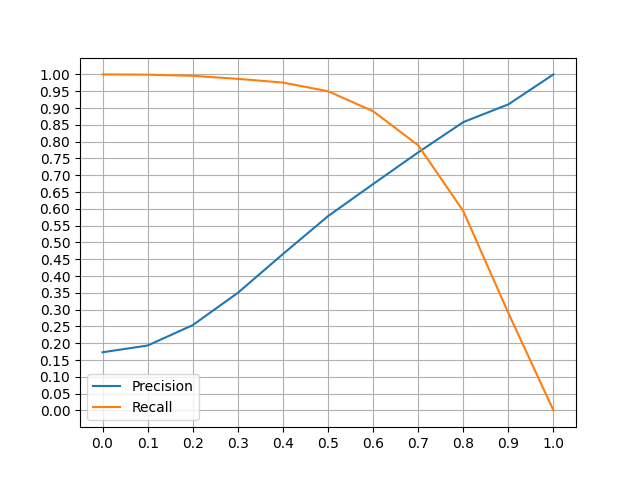
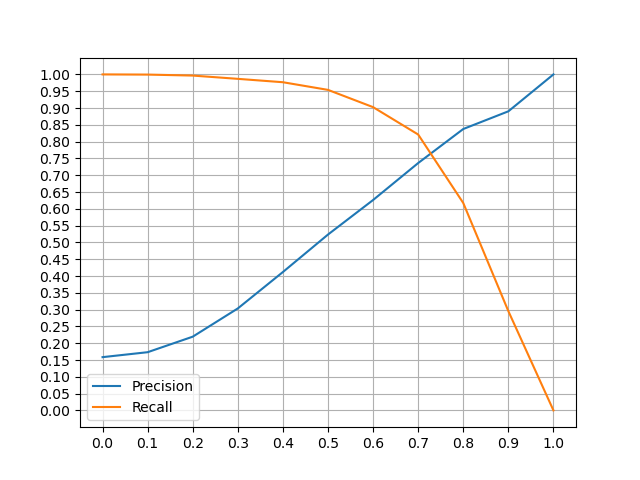
For the evaluation of the models, compressed versions obtained with product quantization were used. In order to measure any performance differences between the original model and the compressed version, Bijeeta et al. model is chosen, with the following features:
- translation of the sequence of key pressed for the password;
-
min_gram = 1; -
max_gram = 4; - epochs = 5.
An effective valutation of both model is based on precision and recall. Not remarkable differences were observed: for this reason only the compressed version of the models are considered.
Euristhics
For a proper evaluation the following euristhics is adopted:
- comparing the password to the lowercase version;
- comparing the password to the uppercase version;
- comparing the password to the
l33tcode version; - verifing if edit distance is greater than 5.
Ground truth and prediction
Ground truth is the ideal result expected and it is used in order to verify how much correct are model prediction. The term prediction refers to the model output after the training. It is applied to new data when is required to verify an event probability.
Ground truth depends on the candidate two passwords and the chosen euristhics, while prediction is obtained thanks to gensim.similarity function of the trained model (which is based on cosine similarity). In case of the work2keypress model, it is important to convert the candidate two password in key presses (w2kp_PRGraph.py).
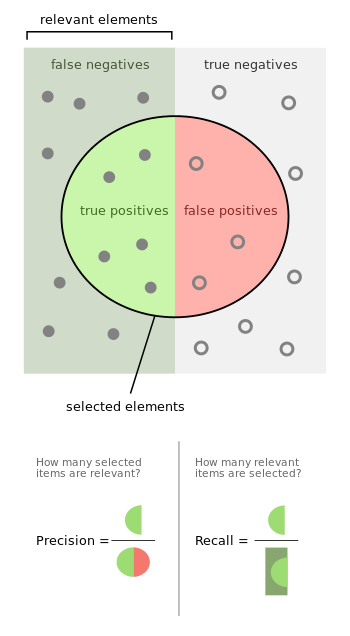
Precision and recall
Precision represents the number of true positive detected from true positives and false positives. Recall represents the number of positive elements detected from a set of false negatives and true positives.
In this case:
- A couple of similar passwords detected correctly represents true positives
- A couple of different password detected as similar are false positives.
- A couple of similar passwords not detected as similar are false negatives.
In order to find out precision and recall it is important to re-define few concepts, according to ground truth and prediction subchapter:
- True positives (TP): its value increments only if both prediction and ground truth have a strictly positive value.
- False positives (FP): its value increments only if ground truth value is zero and if prediction has a strictly positive value.
- False negatives (FP): its value increments only if ground truth value is strictly positive and if prediction value is zero.
$ recall = \frac{TP}{TP + FN} $
Comparing the results of the models
In order to classify passwords, it is necessary to define a threeshold α, which it is chosen considering the best precision and recall values.
- Model with
word2keypress,n_mingram = 1,epochs = 5(Bijeeta et al.): - α = 0.5: precision ≈ 57%, recall ≈ 95%
- α = 0.6: precision ≈ 67%, recall ≈ 89%
- Model without
word2keypress,n_mingram = 2,epochs = 5: - α = 0.5: precision ≈ 65%, recall ≈ 95%
- α = 0.6: precision ≈ 77%, recall ≈ 89%
In this case study, it is more important an higher value of recall. In this way more similar passwords are detected.
It is also important to not have too many false positives identified by couples of password which are different from each other but are considered similar. For this reason I have chosen an higher value of precision, comparing to Bijeeta et al. paper and α = 0.6.
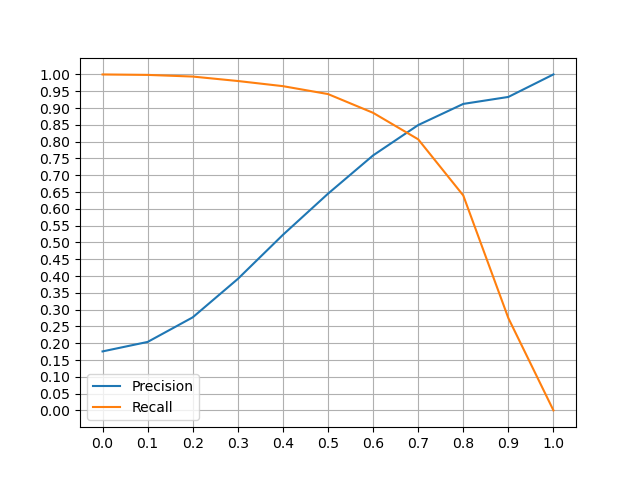
Bijeeta et al. model issues
The worst performances were noticed in the Bijeeta et al. model. The main problems are:
-
word2keypresslibrary translates each character as a key press sequence. When a password is expressed in camel notation, an alternation of capital letters and lowercase letters is present. As a consequence, different passwords in camel notation will be considered similar, because of the repetition of<s>and<c>. - Two passwords expressed as key presses like:
-
$1mp@t1c*which is translated as<s>41mp<s>2t1c<s>8 -
#wlng%p*m}which is translated as<s>3wlng<s>5p<s>8m<s>[ -
SHIFTis translated as<s>: for this reason two passwords which are secure will appear similar. - Setting
n_mingram = 1make the evaluation less precise than usingn_mingram = 2. In fact, in passwords, single characters in passwords do not depend on syntactic rules (unlike in english literature). There are multiple factors really different from each other in order to establish a set of rules for the position of a character in a password, so it is impossible to define how a character is placed.
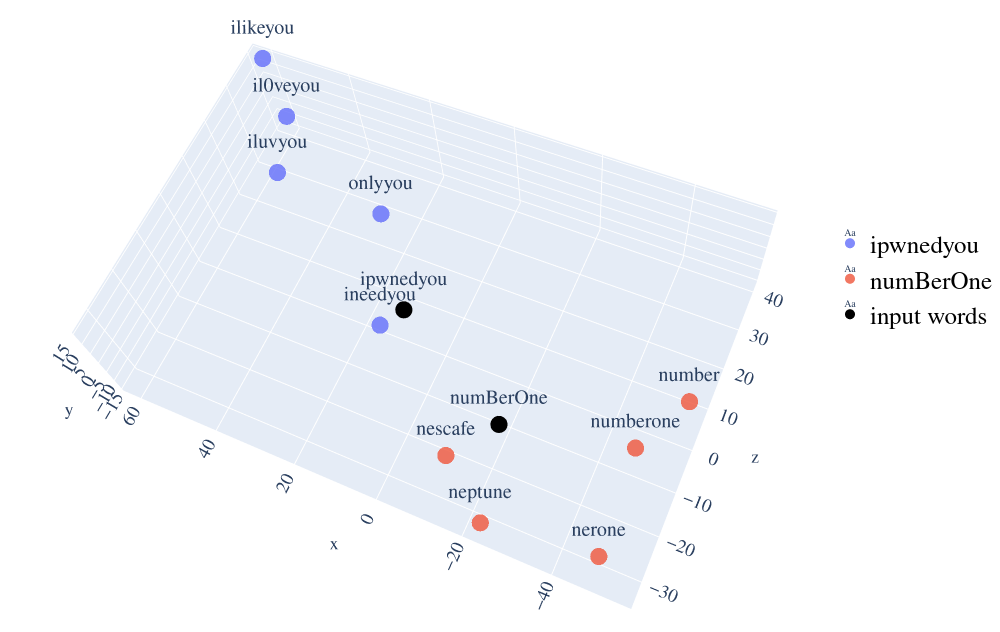
Graphic representation of words distance
File: visualize_embeddings.py
To simplify the comprehension of the project topic, password similarity is represented with a 3-dimensional graphic. t-SNE algorithm is used to reduce the model dimension from 200 to 3. In the next figure it is possible to see the top 5 most similar passwords to ipwnedyou and numBerOne and their distances.
{kind=link}